Как писать robots.txt для uCoz
Что такое robots.txt? Текстовый файл, который задает правила для роботов поисковых систем, что разрешено индексировать, а что нет. В этой заметке мы разберем из чего состоит этот файл, как написать robots.txt самому, и приведем примеры.
Не рекомендуется заменять стандартный robots.txt на сайте uCoz. Он прописан так, чтобы индексировались только страны с информацией, а служебные страницы – нет. Это один из основных элементов внутренней оптимизации сайта.
Вот так выглядит стандартный robots.txt:
Allow: /*?page
Allow: /*?ref=
Allow: /stat/dspixel
Disallow: /*?
Disallow: /stat/
Disallow: /index/1
Disallow: /index/3
Disallow: /register
Disallow: /index/5
Disallow: /index/7
Disallow: /index/8
Disallow: /index/9
Disallow: /index/sub/
Disallow: /panel/
Disallow: /admin/
Disallow: /informer/
Disallow: /secure/
Disallow: /poll/
Disallow: /search/
Disallow: /abnl/
Disallow: /*_escaped_fragment_=
Disallow: /*-*-*-*-987$
Disallow: /shop/order/
Disallow: /shop/printorder/
Disallow: /shop/checkout/
Disallow: /shop/user/
Disallow: /*0-*-0-17$
Disallow: /*-0-0-
Sitemap: http://forum.ucoz.ru/sitemap.xml
Sitemap: http://forum.ucoz.ru/sitemap-forum.xml
Расшифровка каждого пункта ниже.
Из чего состоит robots.txt
Сначала нужно указать, к какому роботу мы обращаемся. Если обращаемся ко всем, то указываем звездочку, а если нужен конкретный, то обращаемся по имени. У Яндекса это YandexBot, а у Google – Googlebot. Это основные индексирующие роботы, узнавайте их имена в справках поисковых систем.
Собственно, вот пример начала для всех роботов:
Далее запрещаем или разрешаем выбранные нами страницы. Используем правило Disallow для запрета и Allow для разрешения. Используя такую структуру, можно например, запретить индексацию определенного раздела, но разрешить в нем же чтение роботом одного документа и т.д.

Вот таким образом мы запрещаем поисковым системам читать наши «sekretiki» (сам директория и адреса начинающие на нее под запретом):
Disallow: /sekretiki/
Спецсимволы и комментарии:
Для того, чтобы запретить только сам раздела без его содержимого, на конце ставится знак $:
Disallow: /sekretiki$
Таким образом, дирректория «/sekretiki» запрещены к индексации, но «/sekretiki.html» допустимы.
Для использования в адресе переменные, используйте звездочки:
Disallow: /sekretiki/*-0-0
Disallow: /news/17-*-0-*
С помощью этих символов, можно сделать правило на запрет индексирования страниц дублей:
Код можно комментировать. Все что находится после # в строке не читается:
Allow: /sekretiki/ # Разрешаю секретики
Disallow: / # Запрещаю индексировать все остальные страницы
User-agent: GoogleBot # Приветствую только робота Google
Disallow: /sekretiki/ # А вот ему я запрещаю именно секретики
Указываем карту сайта Sitemap:
Если не указать ссылку на карту сайта, то робот не сможет быстро индексировать сайт, новые страницы без sitemap.xml могут не попасть в индекс даже в течении нескольких месяцев.
uCoz сам генерирует карту сайта, в том числе и отдельную для форума, поэтому в конце robots.txt указаны такие строки:
Sitemap: http://forum.ucoz.ru/sitemap-forum.xml
Существуют и другой момент в robots.txt, называется Clean-param. Он позволит указать неиспользуемые параметры, не влияющие на содержимое страницы, чтобы робот не заходил на них лишний раз. В uCoz такой тонкой необходимости нет, мы сразу убираем дубли без указания конкретных параметров.
Если вы обнаружили, что на вашем сайте испорчен файл robots.txt, просто удалите его, при запросе система сама подставит правильный robots.txt. Это относится именно к специфики работы с uCoz.
Разбор стандартного robots.txt uCoz:
Теперь, когда вы знаете, из чего состоит файл robots.txt, перейдем к расшифровке стандартного:
User-agent: *— правила касаются всех ботов;Allow: /*?page— разрешить индексировать страницы пагинации;Allow: /*?ref=— разрешить доступ к страницам соц. авторизации;Allow: /stat/dspixel— разрешить доступ к системному скрипту статистики;Disallow: /*?— запретить индексировать URL с параметрами;Disallow: /stat/— запретить индексацию URL статистики;Disallow: /index/1— запретить индексацию Страницы входа;Disallow: /index/3— запретить индексацию страницы регистрации;Disallow: /register— запретить индексацию страницы регистрации;Disallow: /index/5— запретить индексацию системного URL восстановления пароля;Disallow: /index/7— запретить индексацию системного Меню аватарок;Disallow: /index/8— запретить индексацию пользовательских профилей;Disallow: /index/9— запретить индексацию системного URL Истории репутации;Disallow: /index/sub/— запретить индексацию системного URL;Disallow: /panel/— запретить индексацию ПУ;Disallow: /admin/— запретить индексацию ПУ;Disallow: /informer/— запретить индексацию системных информеров;Disallow: /secure/— запретить индексацию системной капчи;Disallow: /poll/— запретить индексацию опросов;Disallow: /search/— запретить индексацию страниц поиска;Disallow: /abnl/— запретить индексацию системных URL;Disallow: /*_escaped_fragment_=— дополнительный запрет на индексацию системных URL;Disallow: /*-*-*-*-987$ —запрет дублей страниц в модулях Новости и Блог, связанных с кодом комментариев на странице;Disallow: /shop/checkout/— запрет на индексацию Корзины для модуля uShop;Disallow: /shop/user/— запрет на индексацию пользовательских профилей для модуля uShop;Disallow: /*0-*-0-17$— дополнительный запрет на индексацию системных URL;Disallow: /*-0-0- —запрет к индексации страниц добавления материалов, списков материалов пользователей, ленточного варианта форума (некоторые дублирующие URL), страниц со списком пользователей (некоторые дублирующие URL), поиска по форуму, правил форума, добавления тем на форуме, различные фильтры (с дублями), страницы с редиректами на залитые на сервер файлы;Sitemap: http://вашсайт.ru/sitemap.xml— ссылка на общую карту сайта;Sitemap: http://вашсайт.ru/sitemap-forum.xml— ссылка на карту форума;Sitemap: http://вашсайт.ru/sitemap-shop.xml— ссылка на карту магазина.
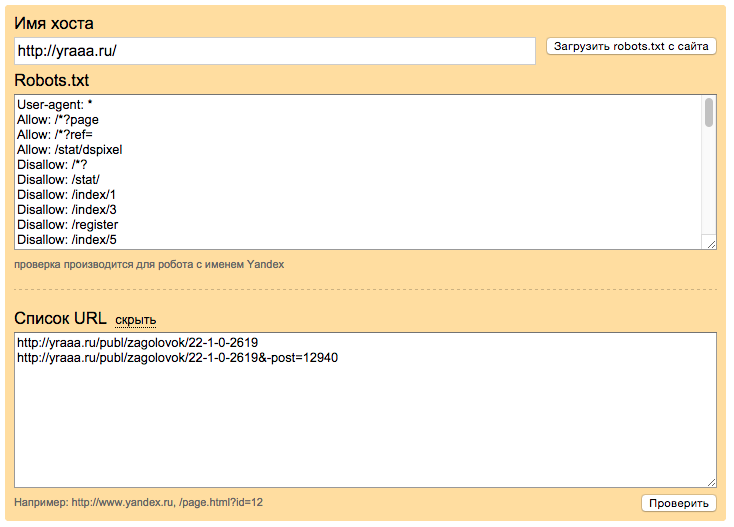
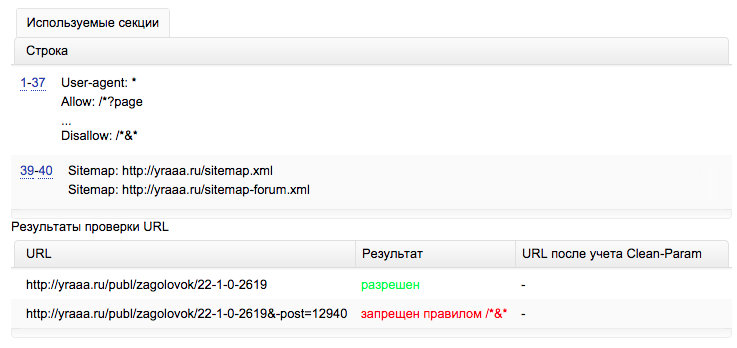
Проверить правильность robots.txt
На Яндексе для вебмастеров создана страница для анализа robots.txt. Просто введите ссылку на сайт и отдельно ссылки на желательные и не желательные для индексации страницы и получите результат:
Зачем вообще прикасаться к файлу robots.txt на uCoz? Это нужно только в том случае, если вы сами не считаете его правильным или же вам нужно разрешить к индексированию, например, страницу регистрации или персональные страницы пользователей.
Источники:
https://yandex.ru/support/webmaster/controlling-robot/robots-txt.xml
http://ucoz.help/robots-txt/